
Enhancing Document Processing with Hierarchical Structure
Researchers
Prof. Ce Zhang, ETH Zürich
Gero Gunkel, Zurich Insurance Company Ltd.
Maurice Weber, ETH Zürich
Description
Automated information retrieval techniques are powerful tools to build knowledge bases from data available in PDF documents, both in private organizations, the public sector, and the sciences. However, while these pools of data contain valuable information, they are typically unstructured, which poses a major obstacle to extracting useful insights using state-of-the-art information retrieval methods. This leads to the need for humans to manually go through hundreds of documents, a process that is not scalable and thus results in large amounts of data being left unexploited.
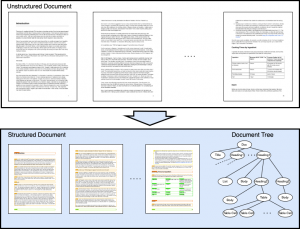
The goal of this project is to build an AI system that brings structure into these documents and thus enables further downstream processing by information retrieval engines. The system takes as input PDF documents and produces structured, intermediate representations of the documents. To achieve this goal, multiple challenges have to be overcome.
First, due to a lack of publicly available large-scale datasets, we build a system that can annotate the hierarchical structure of MS Word, LaTex, RTF, and other document formats at scale. To that end, we make use of structural information extracted from the source code of the documents. By crawling the web for these file types, we use our annotation system to create the first large-scale open dataset with a diverse range of annotated documents, reflecting the distribution of real-world documents composed by humans.
The second challenge is to design and train a large document analysis model which has a general “understanding” of document layouts, their content, and relations between different elements of the documents. As documents are inherently multi-modal, the model design needs to account for this and make use of recent progress in natural language processing, computer vision, and document analysis research.
The third challenge is to design a pipeline that allows researchers and practitioners to fine-tune our models on specific types of documents. As this process often requires organizations to provide infrastructure providers with their data and to respect privacy concerns, we need to develop a technique that enables anonymization, while still maintaining the layout and semantic meaning of the elements present in the documents.