
Mining for Frauds
Status
This project started on the 1st of March 2013 and is now closed.
Researchers
Mario Lucic (ETH)
Srdjan Capkun (ETH)
Andreas Krause (ETH)
Claudiu Duma (Credit-Suisse)
Description
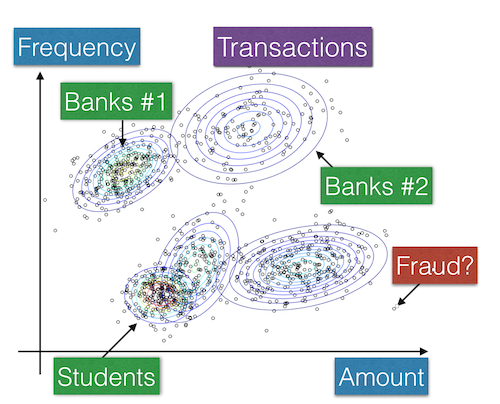
The goal of the project is to create real-time scalable algorithms that detect fraudulent transactions in the context of online banking. The main focus is to develop techniques that work on massive amounts of unlabeled training data. We address several underlying machine learning problems:
- How to do unsupervised training on massive datasets? To this end we develop coresets – a data summarization technique – that allows one to efficiently train provably optimal models. We show how to create these summaries for a variety of unsupervised learning objectives. Perhaps surprisingly, the size of these summaries is independent of the original data set size.
- Given a limited amount of computational resources and large amounts of data, how to efficiently trade-off the computational resources and model accuracy?
In practice one has a limited amount of resources and is willing to tolerate a small error. The critical question is how to produce a good-enough model in the shortest time possible?
We show a summarization-based approach that allows one to efficiently trade-off error, time, data and space usage. - How to perform efficient distance-based outlier detection? We developed a linear-time distance-based technique that, given unlabeled training data, scores the data points according to the likelihood of being an outlier. We demonstrate that this technique outperforms several competing competing methods (KNN, LOF, etc.).
Publications
O. Bachem, M. Lucic, H. Hassani, A. Krause
Approximate K-Means++ in Sublinear Time
Conference on Artificial Intelligence (AAAI), 2016
[PDF]
M. Lucic, M. I. Ohannessian, A. Karbasi, A. Krause
Tradeoffs for Space, Time, Data and Risk in Unsupervised Learning
International Conference on Artificial Intelligence and Statistics (AISTATS), 2015
[PDF]
M. Lucic, O. Bachem, A. Krause
Strong Coresets for Hard and Soft Bregman Clustering with Applications to Exponential Family Mixtures
Technical report arXiv, 2015
[PDF]
O. Bachem, M. Lucic, A. Krause
Coresets for Nonparametric Estimation – the Case of DP-Means
International Conference on Machine Learning (ICML), 2015
[PDF]