
 Anonymization of Voice Recordings for Privacy-Preserving Emotional Analysis
Anonymization of Voice Recordings for Privacy-Preserving Emotional Analysis
Status
This project started in 2022 and has been successfully completed in 2023.
Researchers
Simon Spangenberg, ETH Zurich
Dr. Kari Kostiainen, ETH Zurich
Dr. Giovanni Camurati, ETH Zurich
Industry partner
Zurich Insurance
Description
Motivation
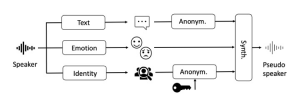
Voice samples reveal information about identity, emotion, and other features of the speaker. Voice anonymization is the process to transform the voice sample of a speaker into the voice sample of a different artificial pseudo-speaker. This has many useful applications, each putting different requirements on the anonymization process. For example, when asked to use voice-based authentication, users might want to use a different and revocable pseudo-voice for each service, to remain protected even if their pseudo-voice is leaked. Clearly, this case has strict requirements on the mapping between real and pseudo-voices, but not on the emotional content of the pseudo-voices. In this project, we focus on the different use case of emotional analysis on audio samples from conversations with the customer service. In this case, the anonymization system is used by the company to protect the identity of the customers before storing, analyzing and sharing the audio samples. In this case, the anonymization system must preserve the emotional content, while providing strong guarantees against deanonymization, but many of the features required for authentication are irrelevant.
Related work
The problem of voice anonymization has been broadly studied in literature. A collection of state-of-the-art techniques has been developed as part of the voice-privacy challenge [1,2,3]. Competing anonymization approaches are evaluated in terms of utility and privacy with both objective and subjective metrics. All approaches fall into two main categories, corresponding to the two baseline pipelines provided by the organizers. The most promising approach consists in synthesizing a new audio sample after having extracted and replaced the identity features (x-vectors) from the original sample. The alternative approach consists in using traditional signal processing techniques to distort the audio samples. With these approaches, evaluating potential privacy leaks is not trivial. Interestingly, the AltVoice [4] project has taken a different path, with a strong focus on security features. In short, AltVoice converts speech into text, and then synthesizes a new voice based on the text and on an artificial identity. While many security guarantees can be provided for the artificial identity, AltVoice suffers from a total loss of other voice features, for example, emotional content.
Our approach
In this project, we aim at improving current approaches in two directions. First, from a security and privacy perspective, we want to define a clear threat model and maximize the protection of customer’s identity. We also want to understand the fundamental and concrete limits of the privacy guarantees that the anonymization approach can provide. Second, from the perspective of the final application, we want to minimize the loss of sentimental information caused by the anonymization.
References
[1] Tomashenko, Natalia, Brij Mohan Lal Srivastava, Xin Wang, Emmanuel Vincent, Andreas Nautsch, Junichi Yamagishi, Nicholas Evans, et al. “Introducing the VoicePrivacy Initiative.” In Interspeech 2020, 1693–97, 2020. https://doi.org/10.21437/Interspeech.2020-1333.
[2] Tomashenko, Natalia, Xin Wang, Emmanuel Vincent, Jose Patino, Brij Mohan Lal Srivastava, Paul-Gauthier Noé, Andreas Nautsch, et al. “The VoicePrivacy 2020 Challenge: Results and Findings.” Computer Speech & Language 74 (July 2022): 101362. https://doi.org/10.1016/j.csl.2022.101362.
[3] “VoicePrivacy 2022.” Accessed May 25, 2022. https://www.voiceprivacychallenge.org/vp2020/.
[4] Turner, Henry, Giulio Lovisotto, Simon Eberz, and Ivan Martinovic. “I’m Hearing (Different) Voices: Anonymous Voices to Protect User Privacy.” arXiv, February 13, 2022. http://arxiv.org/abs/2202.06278.